ProSeNet: Interpretable and Steerable Sequence Learning via Prototypes
Yao Ming, Panpan Xu, Huamin Qu, and Liu Ren
A Brief Introduction
The interpretability of machine learning models is becoming increasingly important for crucial decision-making scenarios. It is especially challenging for deep learning models which consist of massive parameters and complicated architectures.
ProSeNet (Prototype Sequence Network) is a sequence model that is interpretable while retaining the accuracy of sequence neural networks like RNN and LSTM.
ProSeNet is interpretable in the sense that its predictions are produced under a case-based reasoning framework, which naturally generates explanations by comparing the input to the typical cases. For each input sequence, the model computes its similarity with the prototype sequences that we learned form the training data, and computes the final prediction by consulting the most similar prototypes. For example, the prediction and explanation of a sentiment classifier for text based on ProSeNet would be something like:

Here the numbers (0.69, 0.30) indicates the similarity between the inputs and the prototypes. You may find such a framework is similar to k-nearest neighbor models. And yes, the idea of the model originates in classical k-nearest neighbors and metrics learning!
ProSeNet
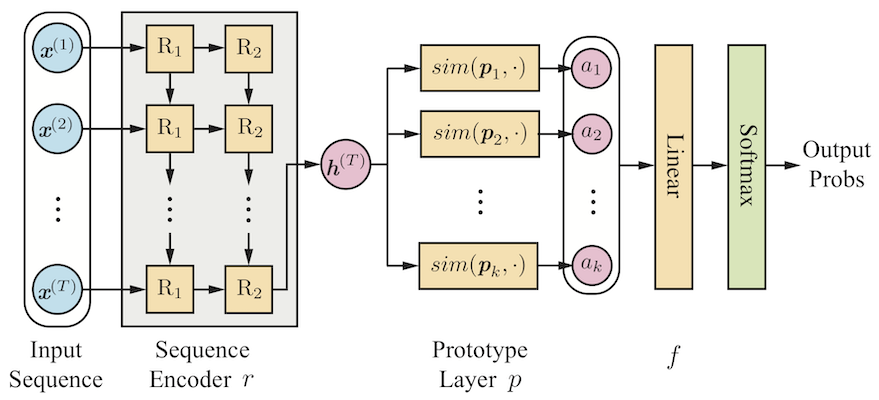
The architecture of the model is illustrated as in the upmost figure. It uses an LSTM encoder r to map sequences to a fixed embedding space, and learns a set of k prototype vectors that are used as a basis for inference. The embedding of the sequence is compared with the prototype vectors and produces k similarity scores. Then a fully connected layer f is used to produce the final output. Here the weight of the layer f assigns the relation between the prototypes and the final classes.
However, the model is still not interpretable, cuz the prototypes are vectors in the embedding space! Thus, we use a projection technique to replace the prototype vectors by its closest embedding vector during training, which associates each prototype vector with a "real" readable sequence. For more details, please check our paper listed below.
Publication
To appear in Proceedings of KDD 19. [preprint]
Video Preview
Acknowledgements
The major idea of the paper, and most of the experiments are done during Yao's internship at Bosch Research North America.
RuleMatrix: Visualizing and Understanding Classifiers using Rules
Yao Ming, Huamin Qu, and Enrico Bertini
Summary
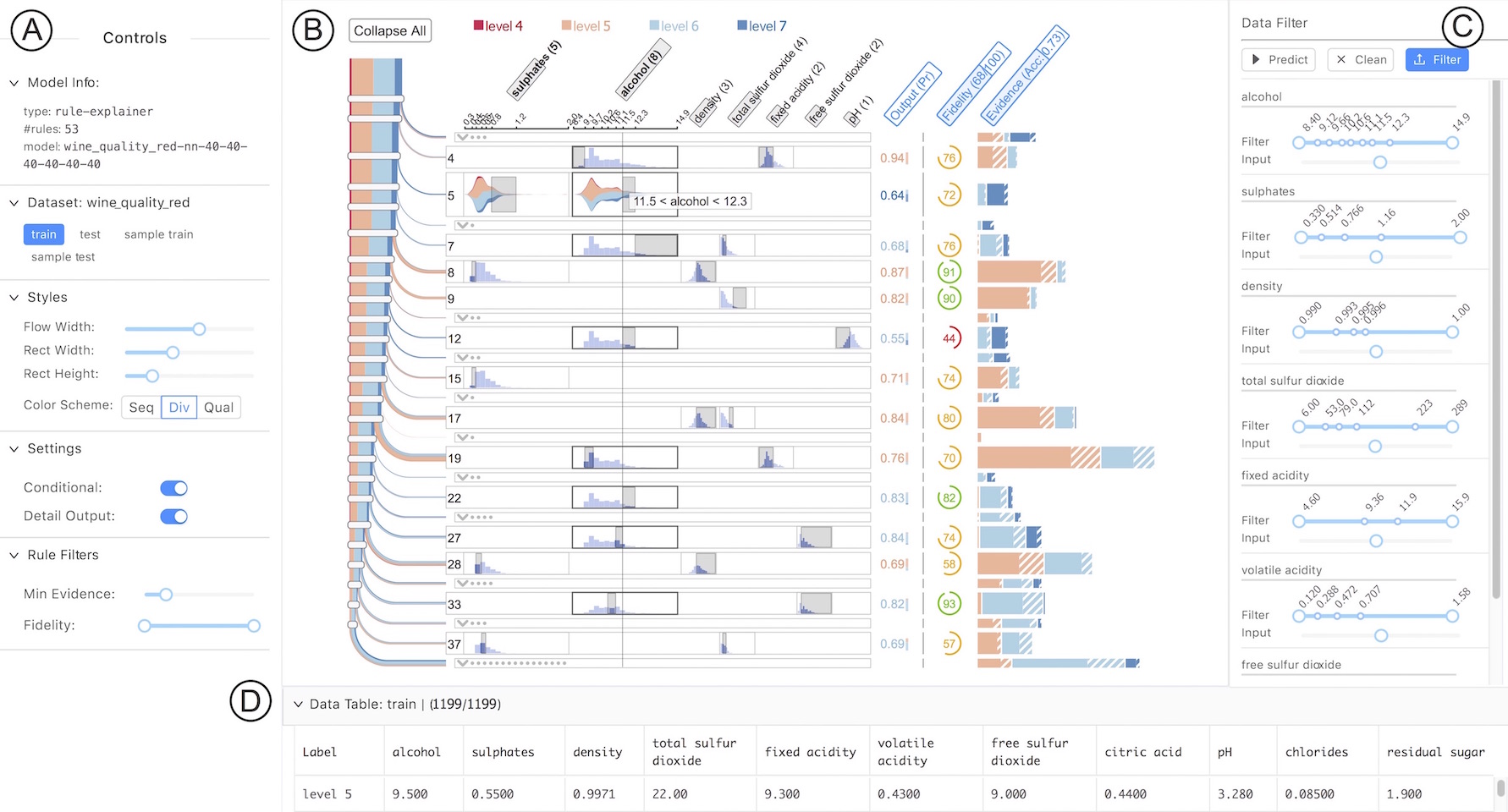
RuleMatrix is an interactive visualization technique that helps users understand the input-output behavior of machine learning models. By viewing a classifier as a black box, we extract a standardized rule-based knowledge representation (a rule list) from its input-output behavior. The extracted rule list is presented as RuleMatrix, a matrix-based visualization, to help users navigate and verify the rules and the black-box model.
Software
The software RuleMatrix and its documentation can be found on Github.
Video Tutorial
Publication
Yao Ming, Huamin Qu, Enrico Bertini. RuleMatrix: Visualizing and Understanding Classifiers using Rules. IEEE Transactions on Visualization and Computer Graphic, 2018 (to appear).
Materials
RNNVis: Understanding Hidden Memories of Recurrent Neural Networks
Yao Ming, Shaozu Cao, Ruixiang Zhang, Zhen Li, Yuanzhe Chen, Yangqiu Song, and Huamin Qu
SUMMARY
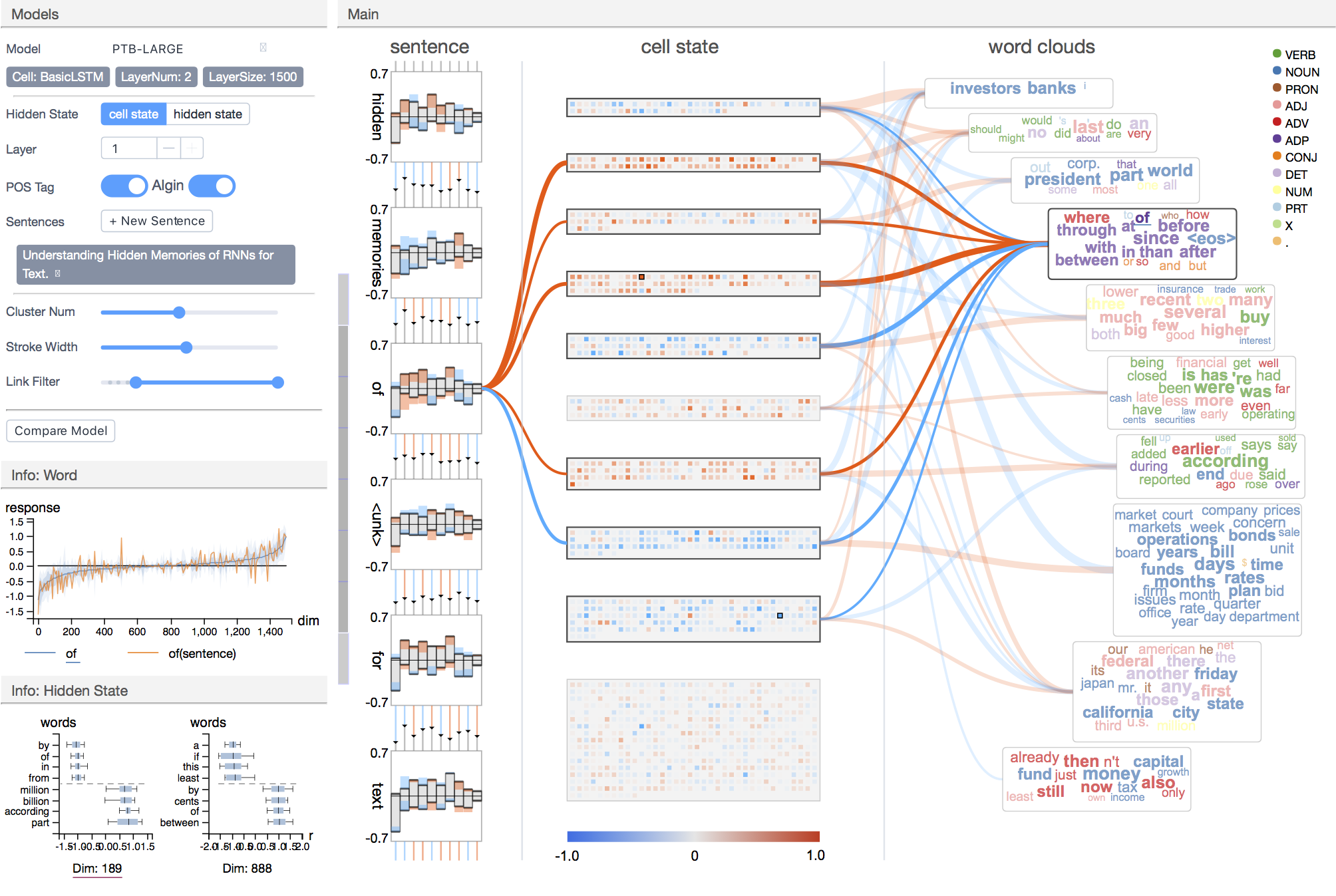
RNNVis is a visual analytics tool for understanding and comparing recurrent neural networks (RNNs) for text-based applications. The functions of hidden state units are explained using their expected response to the input texts (words). It allows users to gain more comprehensive understandings on the RNN's hidden mechanism through various visual techniques.
PUBLICATION
To appear in Proceedings of VAST 17. [preprint]
VIDEOS
[VIS17 Preview]
[Introduction]
CODE
RNNVis is under development. A working demo can be found here. If you have any comments or suggestions, feel free to open an issue.
DATA
This project has used the following dataset:
- Penn Tree Bank: [data source] [paper]
- Yelp Data Challenge: [data source]
- A collection of Shakespeare’s work (used in supplement case study): [data source]